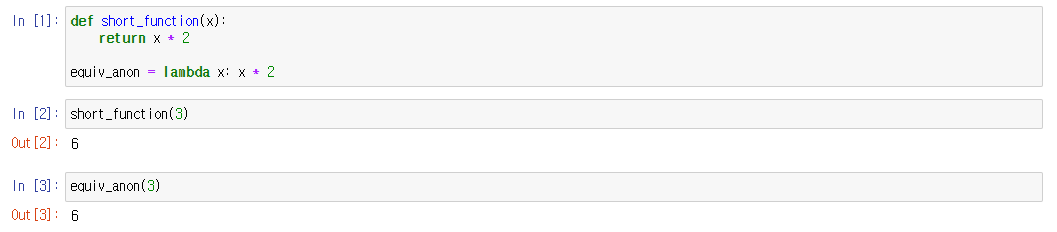
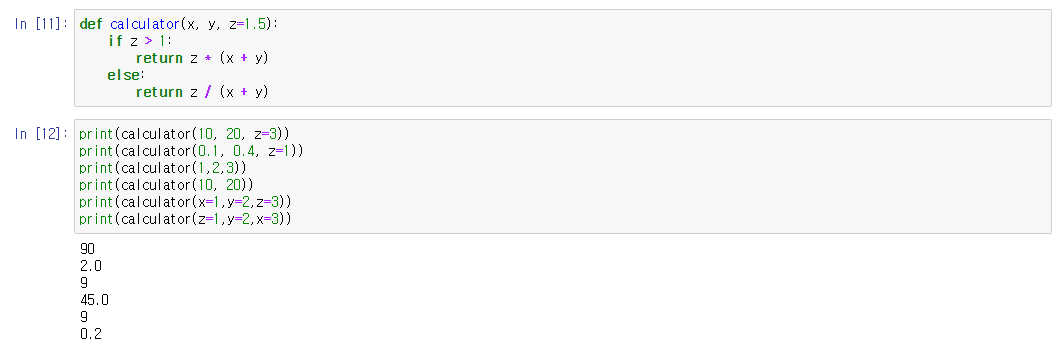
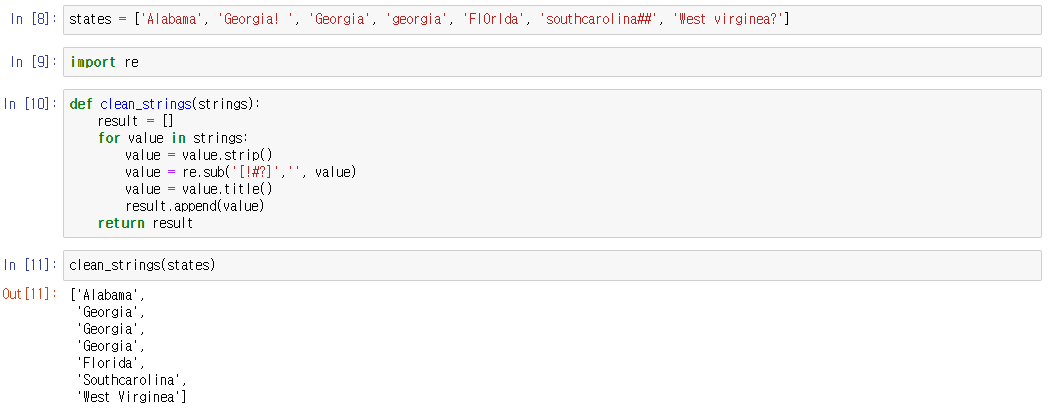
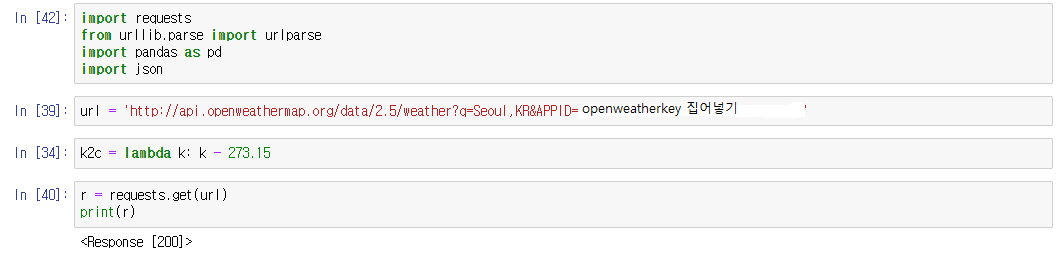
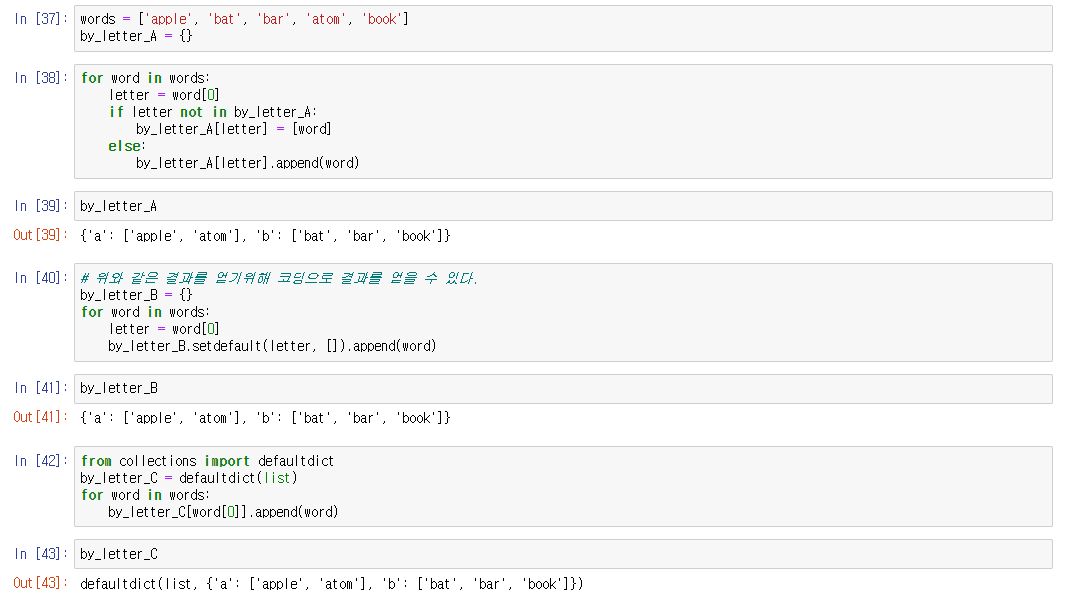
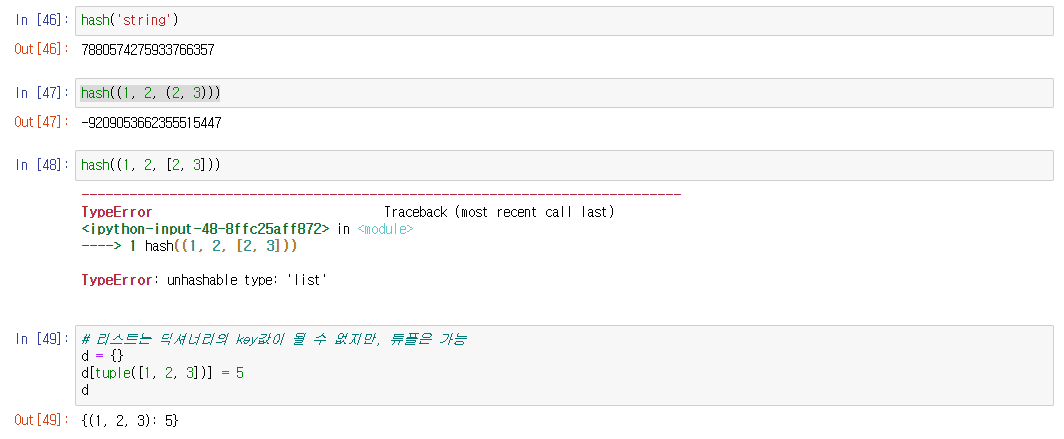
파이썬에서 데이터를 불러왔을 때 문자가 깨져서 보이는 경우때문에 들어오신 경우 인코딩 형식에 문제가 있을 수 있습니다. 길지 않은 내용이니 천천히 읽어보시고 참고하시기 바랍니다.(해결방법은 맨 아래에 있습니다)
데이터 포맷은 크게 "텍스트 데이터"와 "바이너리 데이터"로 나눌 수 있습니다.
텍스트 데이터란 일반적으로 텍스트 에디터로 편집할 수 있는 데이터 포맷을 나타냅니다. 주로 일반적인 자연 언어(한국어, 영어 등)와 숫자 등으로 구성됩니다. 특수하게 줄바꿈과 탭 등의 제어 문자도 포함되어 있는데, 그 밖에는 모두 에디터에서 시각적으로 확인할 수 있는 데이터 형식입니다.
프로그래밍 언어의 소스코드도 텍스트 데이터라고 말할 수 있습니다. XML/JSON/YAML/CSV처럼 웹에서 주로 사용되는 데이터 포맷은 텍스트 데이터를 기반으로 합니다.
바이너리 데이터란 문자와 상관 없이 데이터를 사용할 수 있는 데이터 영역을 활용하는 데이터 형식입니다.
바이너리 데이터는 문자에 할당되는 영역 외의 영역도 사용하므로 일반적인 텍스트 에디터로는 열 수 없습니다. 또한 사람이 시각적으로 확인해도 의미를 알 수 없는 문자열로 표현됩니다. 이에 대한 예시를 살펴보겠습니다.
다음과 같이 a.bin에 data = 100이라는 내용과 a.txt에 100이라는 내용을 적은 후 저장해서 용량을 살펴보겠습니다.


그리고 나서 용량을 확인해 보니
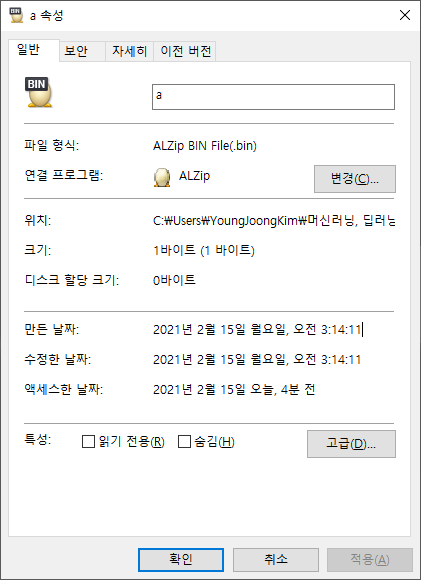
a.bin의 용량은 1byte가 나왔고,
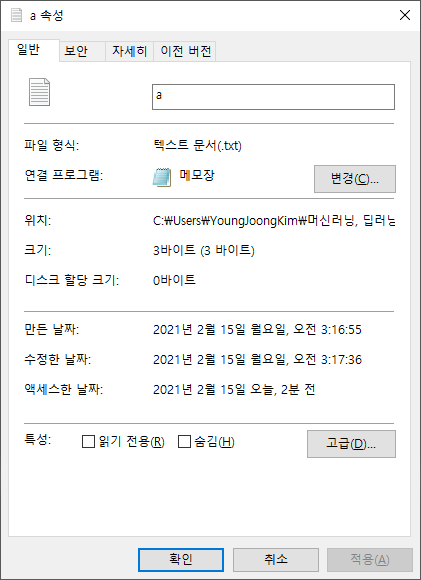
a.txt의 용량은 3byte가 나왔습니다.
똑같은 100을 표현하는데 있어 텍스트는 3byte, 바이너리는 1byte이므로 데이터를 저장하는데 있어 바이너리가 효율적이라는 것을 알 수 있습니다.
텍스트 데이터 및 바이너리 데이터의 장단점을 표로 비교해보면 다음과 같습니다.
| 데이터 종류 | 장점 | 단점 |
| 텍스트 데이터 | 텍스트 에디터가 있다면 편집할 수 있습니다. 또한 설명을 포함할 수 있으므로 가독성이 높습니다. | 바이너리 데이터에 비해 크기가 큽니다. |
| 바이너리 데이터 | 텍스트 데이터에 비해 크기가 작습니다. | 텍스트 에디터로 편집할 수 없습니다. 어떤 바이트에 어떤 데이터가 있다고 정의해야 합니다. |
오늘날의 CPU는 기억 매체의 용량이 큽니다. 즉 1byte를 처리하나 3byte를 처리하나 처리 속도에는 큰 차이가 없습니다. 따라서 누구나 열어볼 수 있고 편집할 수 있게 텍스트 데이터를 사용하는 것이 더 좋다고 생각합니다.
하지만 웹에서는 크기가 조금 크더라도 텍스트 데이터가 더 편리하기 때문에 더 많이 사용될 것 같지만, 사실 대부분이 바이너리 데이터를 사용합니다. 왜냐하면 이미지와 동영상 같은 파일은 용량이 크므로 최대한 서버의 부하를 줄이기 위해 크기를 압축해야 하기 때문입니다. 물론 텍스트 기반으로 하는 이미지 형식도 있지만 거의 사용되지 않습니다. 이미지 또한 바이너리 형식을 사용하는 것이 훨씬 실용적이기 때문입니다.
시각적으로 확인할 수 있는 텍스트 데이터도 주의할 것이 있습니다. 바로 문자 인코딩입니다.
어떠한 데이터를 다운로드 받은 후 불러올 때 문자가 깨지는 경우를 보신적이 있으실텐데요. 데이터를 저장한 사람이 저장할 때 인코딩을 UTF-8 혹은 EUC_KR로 하냐에 따라 저장되는 데이터는 전혀 다르기 때문입니다.
그래서 EUC_KR로 저장을 했는데 불러올 때 UTF-8로 불러온다면 문자가 깨진듯한 현상을 볼 것입니다.
만약 그러하다면 UTF-8로 불러오신 분은 EUC_KR로 바꿔보신 후 다시 실행해보시고, EUC_KR로 불러오신 분은 UTF-8로 바꿔보신 후 다시 실행해보시면 해결이 잘 될수도 있으니 참고하시기 바랍니다.
최근에는 텍스트 데이터 기반으로 하는 데이터는 모두 UTF-8로 인코딩이 되어 있습니다. 이는 HTML5 표준에서 UTF-8을 사용하는 것을 권장하기 때문입니다. 하지만 한국에서는 아직도 EUC_KR을 사용하는 경우가 많기 때문에 이 부분에 주의하시기 바랍니다.
'Data organization > 개념정리' 카테고리의 다른 글
| 에러와 예외 처리 (0) | 2021.02.17 |
|---|---|
| 함수란?(Function) (0) | 2021.02.12 |
| Comprehension(리스트, 딕셔너리) (0) | 2021.02.12 |
| 파이썬 연산(집합) (0) | 2021.02.03 |
| 딕셔너리(Dictionary) (0) | 2021.02.03 |