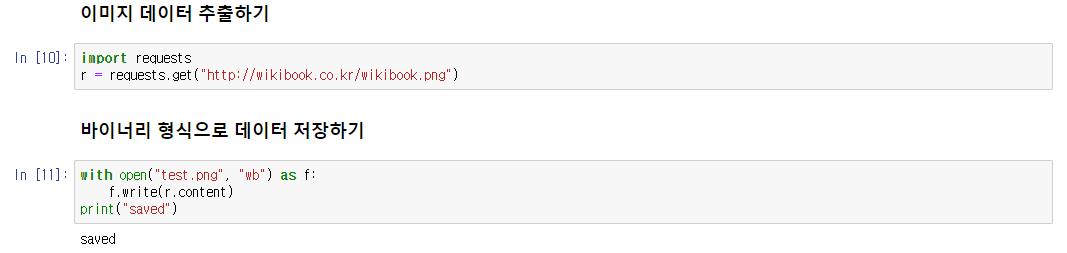
오늘은 전 세계의 모든 날씨 정보 등을 가지고 있는 OpenWeatherMap을 사용해서 서울의 날씨정보에 대해 알아보려고 합니다.
일단 앞서 OpenWeatherMap을 사용하려면 개발자 등록을 하고 API키를 발급받아야 합니다.
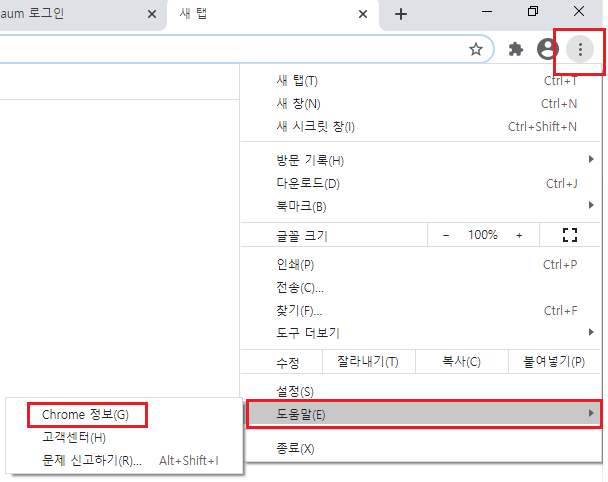
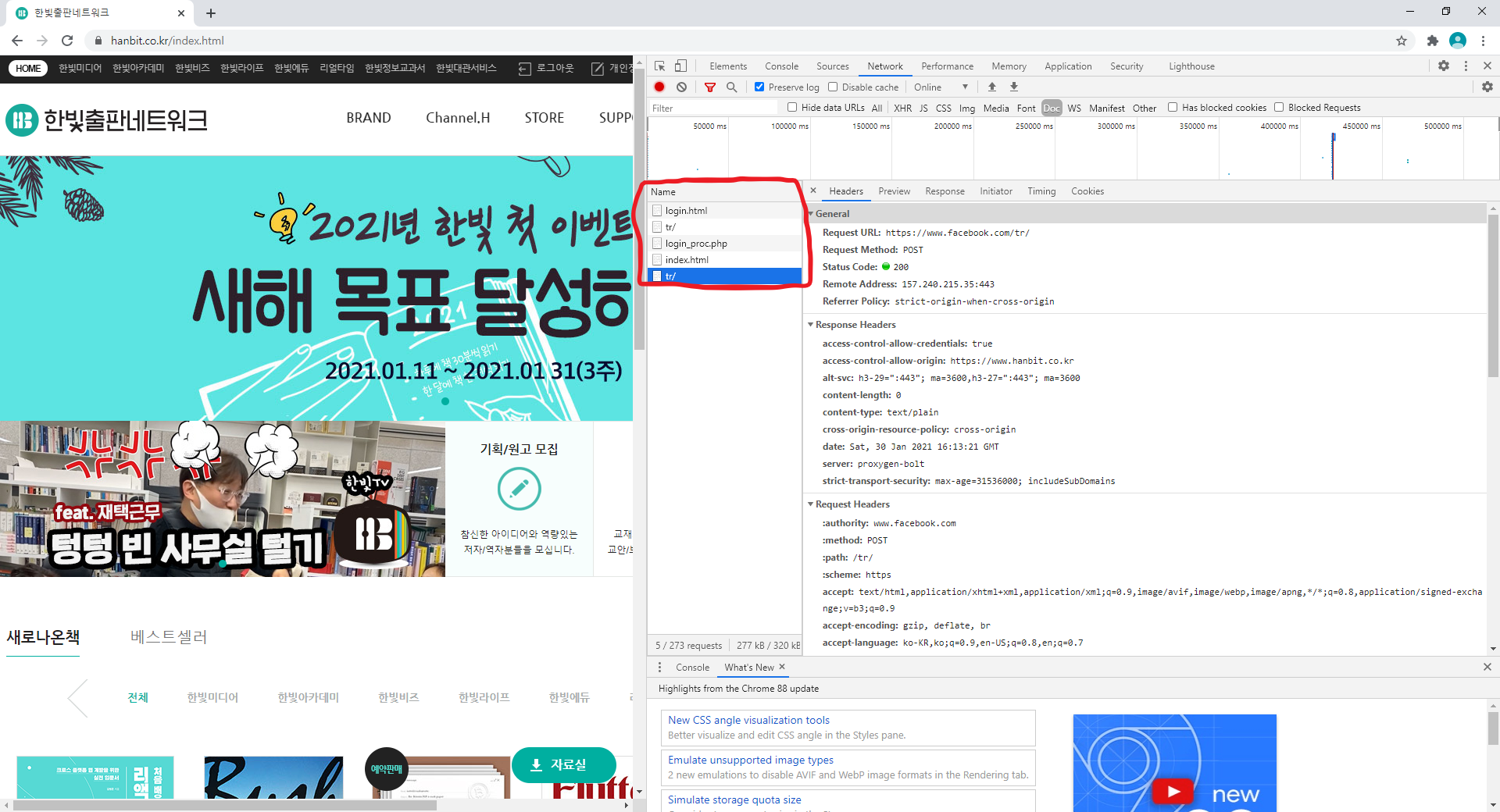
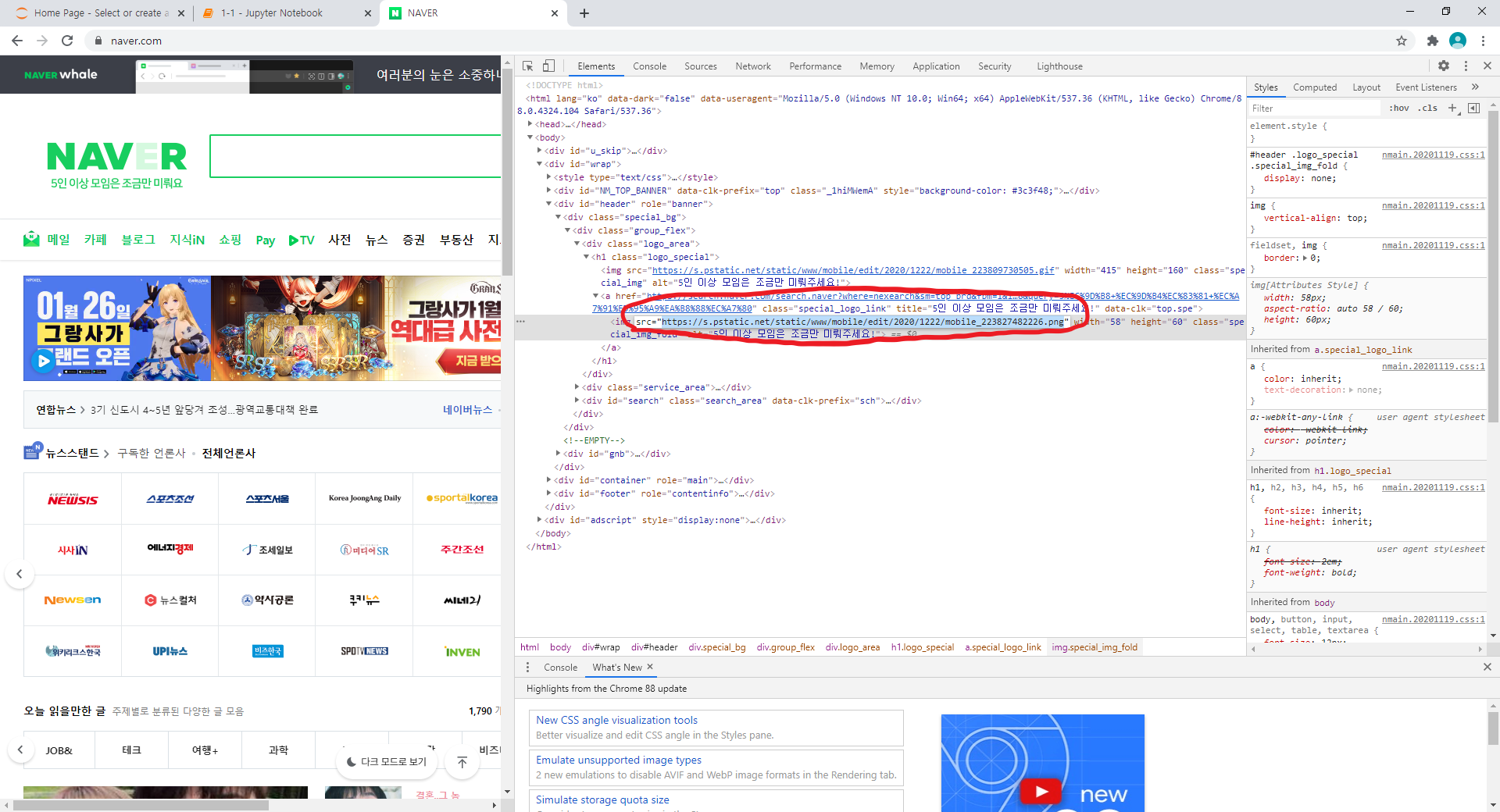
http://openweathermap.org/ 에 가셔서 가입을 누르시면 어디에 사용할 지 물어보는데 적당한 답변을 주시고 OK버튼을 눌러주세요 그리고 오른쪽 상단에 본인 아이디를 누르시면 여러가지 메뉴가 나오는데 거기서 [My API Keys]라는 탭에서 API 키를 확인하실 수 있습니다.
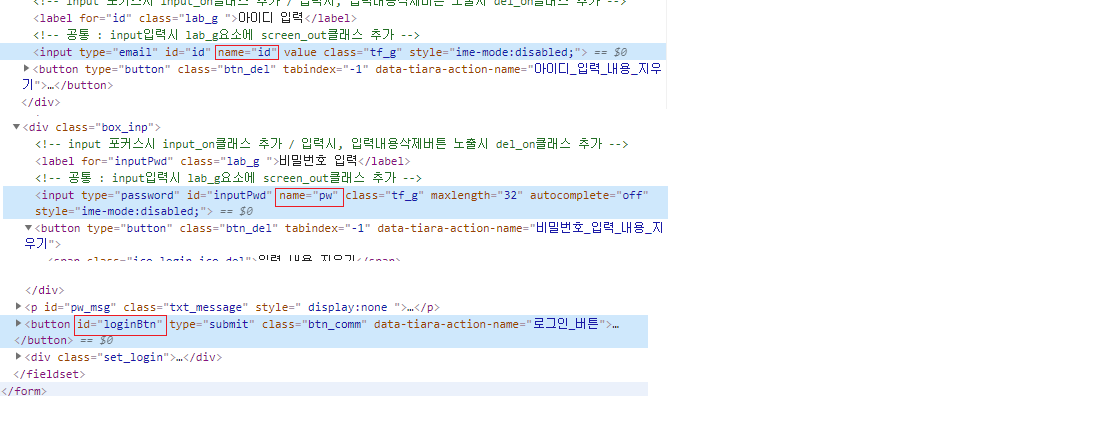
제 API key는 개인정보 보호를 위해 지웠지만 다음과 같이 key를 얻을 수 있고, 이 key를 사용하여 데이터를 가져올 수 있습니다.
OpenWeatherMap은 기본적으로 유료 API이지만 현재 날씨, 5일까지의 날씨는 무료로 사용할 수 있습니다. 다만 무료로 사용시 1분에 60번만 호출할 수 있습니다. 실제 애플리케이션에 적용하는 것이 아닌 연습용으로는 충분할 것입니다.

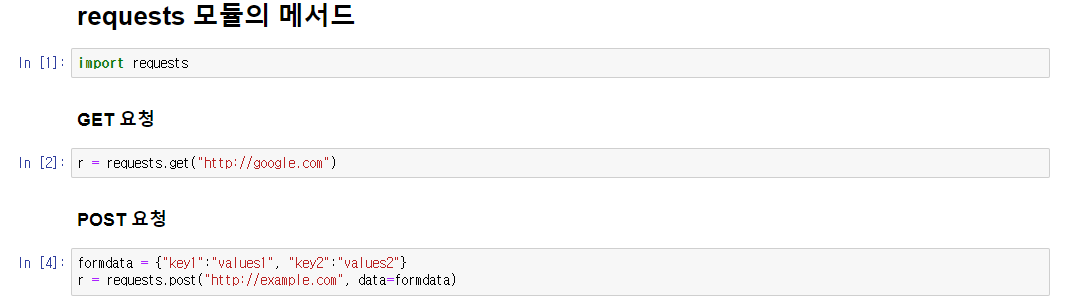
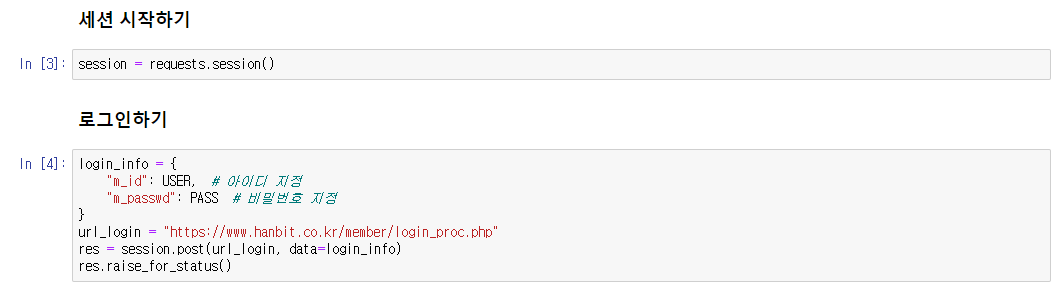
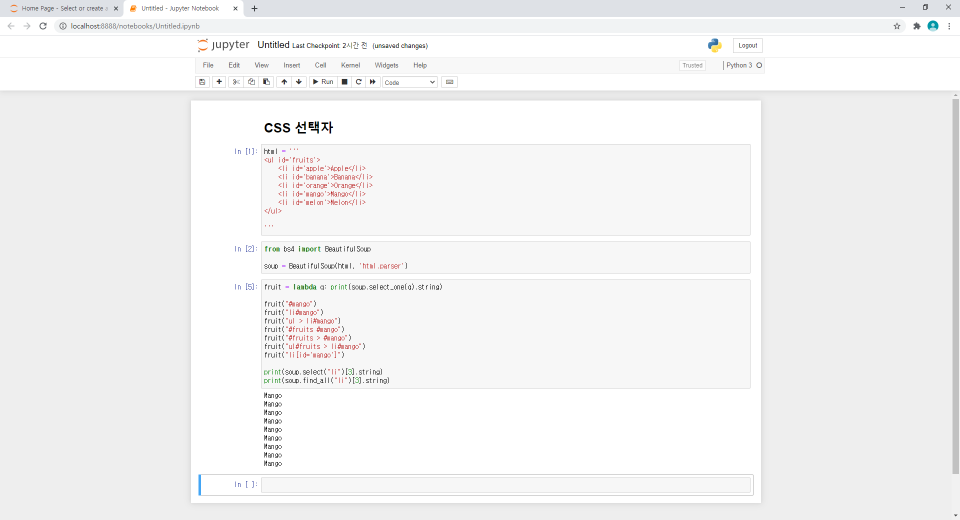
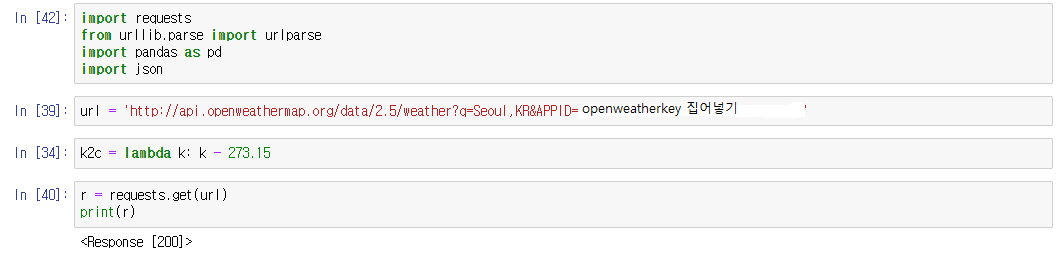
1. request, json을 import 한 후, API키를 지정 후 requests를 활용하여 데이터 받아오기
그리고 url을 지정을 해 주는데, 저는 일단 한국에 있는 서울의 날씨 정보만 가져올 것이기 때문에 url에 직접 입력을 했습니다. url = 'http://api.openweathermap.org/data/2.5/weather?q=(도시,나라)&APPID=(openweathermap으로부터 발급받은 key)' 이런식으로 입력을 해줍니다.
k2c는 화씨를 섭씨로 바꾸기 위한 간단한 수식이며, requests.get(url)을 이용하여 데이터를 받아옵니다. 결과가 200이 나왔다는 것은 정상적으로 데이터를 받아왔다는 것을 의미합니다.
2. jason을 이용한 결과값
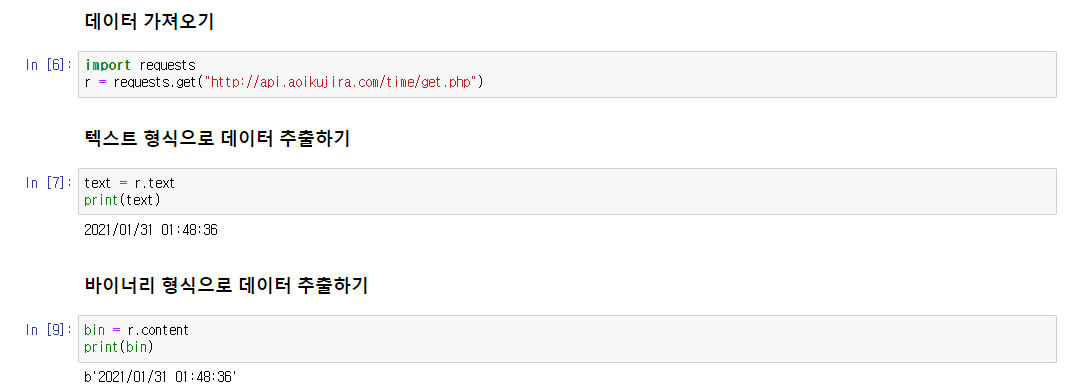
받은 데이터는 풀어주면 다음과 같은 결과를 볼 수 있습니다.
데이터는 기본적으로 딕셔너리와 리스트로 되어있기 때문에 이를 잘 활용하면 원하는 데이터를 보기 좋게 추출할 수 있습니다.

3. 원하는 데이터 정리
data의 내용을 보면 coord는 위도 및 경도, weather 키 값은 id, 날씨, 설명, 아이콘 그리고 main에는 온도, 체감온도, 최저 및 최고온도, 압력, 습도 등등 그 밖에의 여러 정보들을 확인하실 수 있습니다.
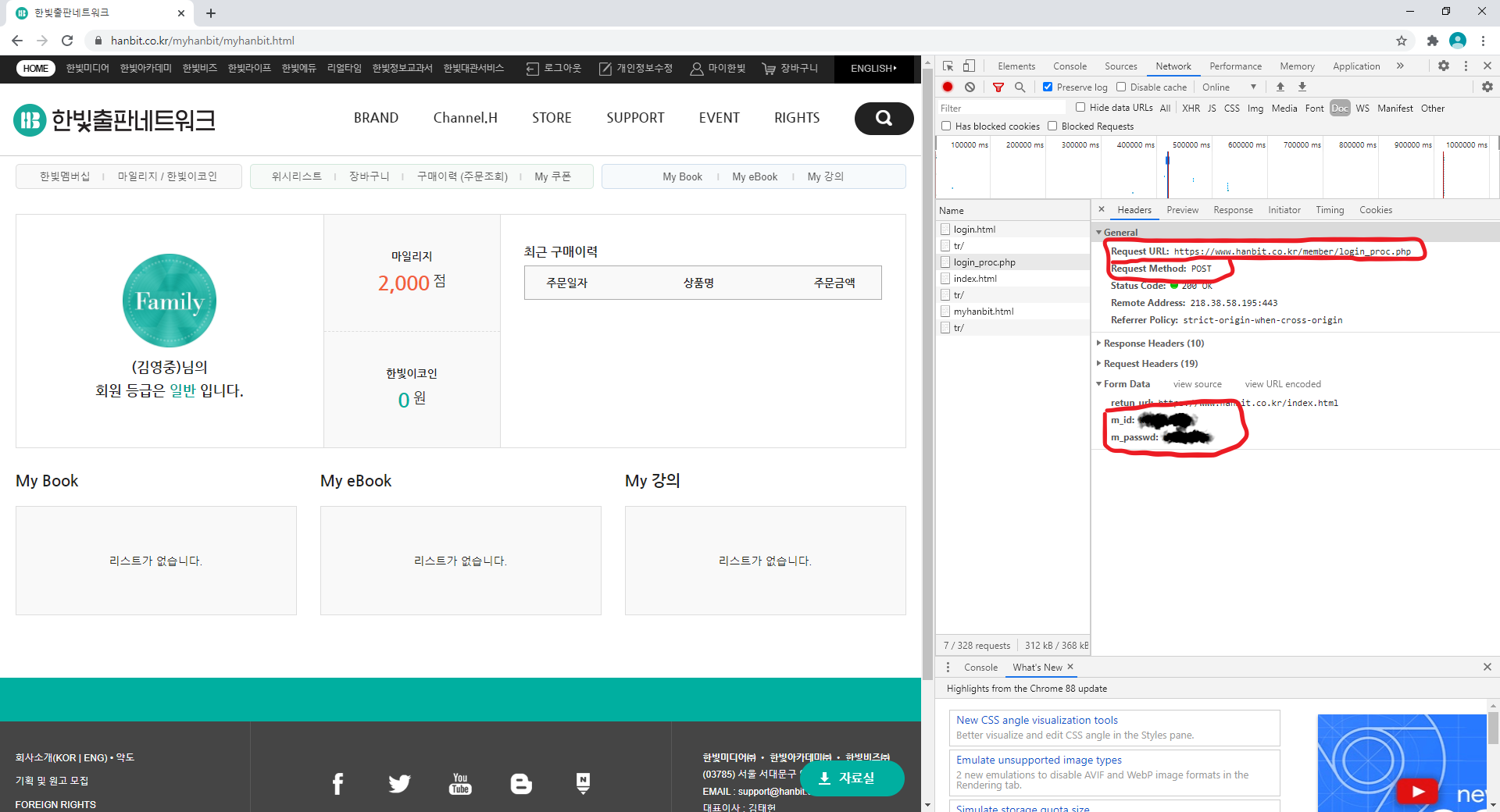
저는 그 중 도시명, 날씨, 최저 및 최고 기온, 습도, 기압, 풍향, 풍속등만 추출하였고, 다음과 같은 결과값을 얻었습니다.

'AI > 데이터 수집' 카테고리의 다른 글
| Selenium으로 스크레이핑하는 방법 (0) | 2021.02.02 |
|---|---|
| Selenium을 활용한 로그인 (0) | 2021.02.02 |
| requests 모듈의 메서드 (0) | 2021.01.31 |
| requests를 사용하여 로그인 (0) | 2021.01.31 |
| 상대경로 및 절대경로 (0) | 2021.01.26 |