"코딩을 잘하는 프로그래머라면 예외 처리를 잘해야 한다"라고 저에게 교수님께서 알려주셨던 것이 기억이 납니다.
그만큼 코딩하는데 있어서 예외처리는 굉장히 중요한 부분을 차지하고 있는데요, 만약 예외처리가 잘 안된 상태에서 서버를 돌리다가 예외가 발생하면 큰 문제가 발생할 수도 있기 때문입니다.
에러가 발생하는 원인은 원래 특정한 종류의 입력만 처리하도록 조건을 주어줬는데, 그에 맞지 않은 입력을 할 경우가 있습니다.
대표적으로 비밀번호를 예로 들어보겠습니다. 대문자, 소문자, 숫자, 특수기호(!#%^)를 모두 사용하여 8~16자리의 비밀번호 생성이라는 조건을 준 웹사이트를 가끔 보실 수 있으실 것입니다. 그렇다면 저 조건중에 한가지라도 빠지게 된다면 에러메세지를 보낸 뒤 다시 생성하라고 하는 경우를 경험하신 경우가 있으실 겁니다.
만약 저 상태에서 예외처리를 하지 않았다면 서버에 큰 문제가 발생하여 운영에 큰 어려움이 생길지도 있으므로 예외처리는 그만큼 중요하다고 생각합니다.
1. ValueError
다음은 문자를 소수로 바꿔주는 명령어 float를 사용하여 ValueType의 에러를 살펴볼까 합니다.

float안에는 ''안에 소수가 들어와야 정상적으로 결과가 나오는데, 만약 something같은 문자열을 입력한다면 다음과 같이 ValueError가 나오게 됩니다.
2. TypeError
이번에는 float안에 숫자를 적었지만, 튜플 형식으로 적어 넣어 TypeError이 발생하는 경우입니다.

3. Try, Except
위의 문제점을 해결하기 위해 Try, Except를 사용해 보겠습니다.
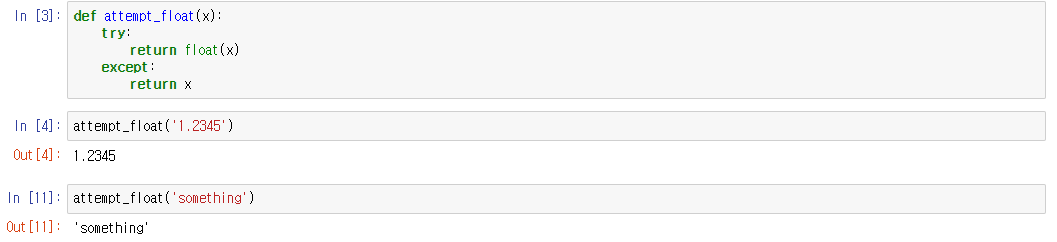
attempt_float()라는 함수를 그 안에 try와 except를 넣어줘서 try에서 에러가 발생할 경우 except에서 처리할 수 있도록 조치를 취했습니다.
여기서 except에 다시한번 더 조건을 줄 수 있는데 에러의 종류에 따라 처리방식을 달리 하고 싶은 경우 다음과 같이 써줍니다.

except옆에 ValueError를 입력하고 TypeError가 발생하니 바로 다음과 같이 결과가 나왔습니다.
여기서의 방법은 처음처럼 except옆에 아무것도 쓰지 않으면 모든 종류의 에러를 아래와 같이 처리할 것이며, 혹은 튜플형식으로 두가지 에러 조건을 넣어 다시 실행해 보겠습니다.

TypeError와 ValueError이 모두 정상적으로 처리가 된 것을 확인하실 수 있습니다.
4. Finally
Try블록이 성공적으로 수행되었는지 여부와 관계없이 실행시키고 싶은 코드는 finally블록을 이용하여 적어줍니다.
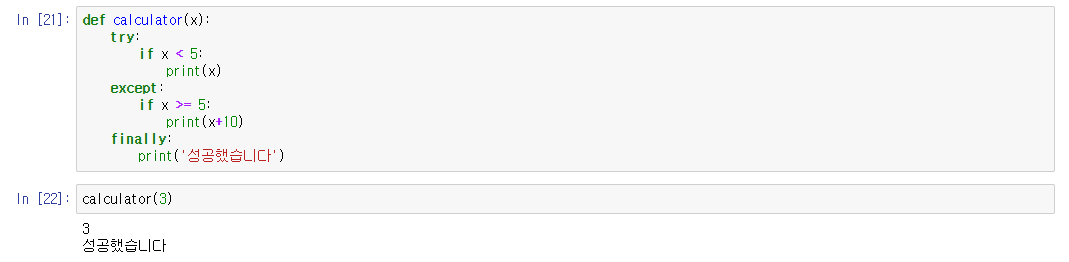
다음과 같이 try블록에서 수행 후 finally도 바로 실행된 것을 확인하실 수 있습니다.
'Data organization > 개념정리' 카테고리의 다른 글
| 문자가 깨지는 경우 해결방법(텍스트 데이터와 바이너리 데이터) (0) | 2021.02.15 |
|---|---|
| 함수란?(Function) (0) | 2021.02.12 |
| Comprehension(리스트, 딕셔너리) (0) | 2021.02.12 |
| 파이썬 연산(집합) (0) | 2021.02.03 |
| 딕셔너리(Dictionary) (0) | 2021.02.03 |