함수는 파이썬에서 코드를 재사용하고 조직화하기 위한 가장 중요한 수단이다.
같은 일을 반복하거나 비슷한 코드를 한 번 이상 실행해야 할 것이 예상되면, 재사용 가능한 함수를 작성하는 것이 더 나을 것이다.
함수를 쉽게 설명하기 위해 옷을 판매하는 회사와 공장에 비유해보겠다.
일단 어느 한 회사가 옷을 생산하기 위해 공장에 OEM으로 주문을 넣었다고 생각을하자,,
회사는 옷을 가공하기 위한 자재를 직접 공장에 전달한다.
이 자재를 이용하여 공장에서는 설계에 맞게 옷을 제작하고 제작이 완성된 옷을 다시 회사에 넘기게 된다.
함수 역시 같은 원리이다. 함수에 필요한 변수를 넣어주고 조건문을 거쳐 나온 값을 return으로 받게 되는 것이다.
(이 때 함수는 파이썬 명령들의 집합과 연관된 이름을 지어 좀 더 가독성이 좋은 코드를 작성할 수 있도록 해준다.)
예를 들어 함수를 작성해보면 다음과 같다.
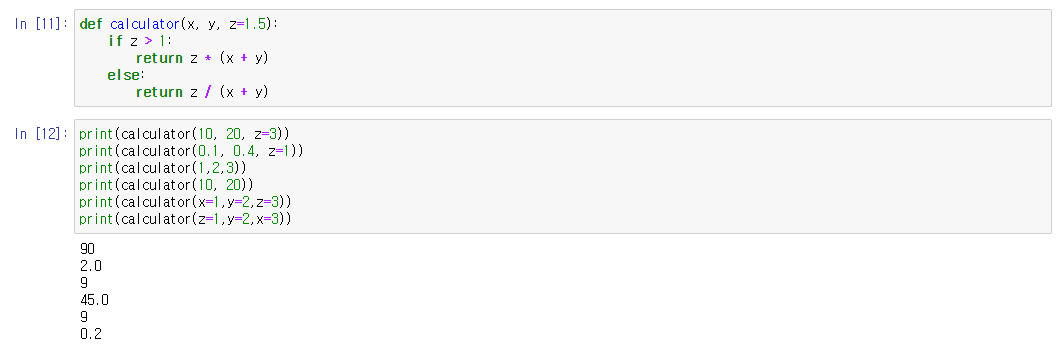
함수명은 calculator로 가독성이 좋아지도록 함수의 성질과 연관된 이름으로 지었다.
함수를 살펴보면 x, y, z=1.5로 되어있다.(x,y는 default값이 없고, z는 default값이 1.5)
그래서 첫 번째 (10, 20, z=3)이라는 변수를 calculator라는 함수에 넣어줬고 결과값으로 90을 얻었다.
계산을 해보면 z > 1이므로 3 * (10 + 20) = 90이 된다.
두 번째 변수(0.1, 0.4, z=1) 역시 z의 조건이 z는 1 이하이므로 1 / (0.1 + 0.4) = 2 라는 결과를 얻을 수 있었다.
그렇다면 함수에 변수를 넣는 방식을 4가지 더 실험을 해보았다.
1. 'z='을 없앤 경우
2. z의 변수를 기입하지 않은 경우
3. x=, y= 이라는 변수를 넣어준 경우
4. z를 맨 처음 그리고 x를 마지막에 넣은 경우
1번의 경우 'z='이라는 단어를 굳이 쓰지 않아도 같은 결과값을 얻을 수 있었다.
3 * (1 + 2) = 9로 결과값이 맞게 나왔다.
2번의 경우 z의 변수를 넣어주지는 않았지만 기존에 default값으로 1.5가 주어졌기 때문에 z=1.5로 계산되어 결과값을 얻었다.
1.5 * (10 + 20) = 45로 결과값이 맞게 나왔다.
3번의 경우 x=, y=이라고 다른 방식으로 넣었지만 역시나 3 * (1 + 2) = 9로 결과값이 맞게 나왔고
마지막 4번의 경우,
z를 맨 처음, x를 맨 마지막에 써줘도 변수명을 정확히 기입을 해주었기 때문에 그에 따른 값으로 결과값이 나왔다
1 / (2 + 3) = 0.2로 결과값이 맞게 나왔다.
위에서 공부한 내용을 바탕으로 실제 데이터 가공을 하기 위해 어떻게 사용되는지 살펴보자.
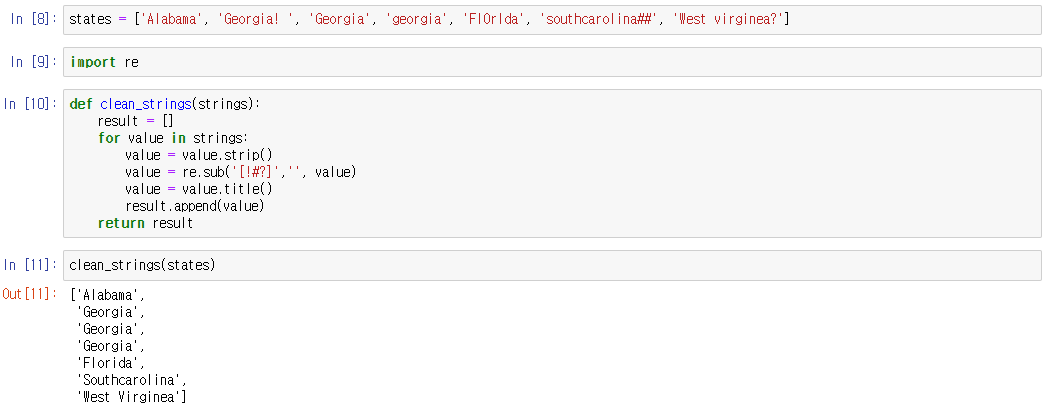
states에 불규칙한 대소문자 및 기호 그리고 띄어쓰기를 넣어두고 re라는 표준라이브러리를 불러온 후, 문자열을 가공해주는 함수를 만들었다.
strip()은 value안의 문자열에 있는 양쪽 끝에 있는 띄어쓰기를 제거해주고,
sub()에서 첫 번째 ('[!#?]')의 의미는 이 안의 기호 대신 두 번째 ('')로 대체하라는 의미이다. 즉, !#?의 기호를 없애라는 의미로 해석할 수 있다.
마지막으로 title()은 문자열이 시작하는 첫 번째 문자만 대문자, 나머지 문자는 전부 소문자로 만들어 주는 명령어이다.
states라는 리스트를 함수 clean_strings(states)로 실행하니 데이터가 깔끔하게 가공된 것을 알 수 있다.
'Data organization > 개념정리' 카테고리의 다른 글
| 에러와 예외 처리 (0) | 2021.02.17 |
|---|---|
| 문자가 깨지는 경우 해결방법(텍스트 데이터와 바이너리 데이터) (0) | 2021.02.15 |
| Comprehension(리스트, 딕셔너리) (0) | 2021.02.12 |
| 파이썬 연산(집합) (0) | 2021.02.03 |
| 딕셔너리(Dictionary) (0) | 2021.02.03 |